What we found testing Whisper-1 on Wolof in 2026.
OpenAI's whisper-1 posts the highest mean WER (1.05) of any commercial system in our 104-sample Senegalese voice benchmark. Here is what that number looks like in production.
By Abdoul Aziz Kane, Kuma Labs8 min read
A WER of 1.05 means the model produces, on average, more substituted, inserted, or deleted tokens than the reference transcript actually contains. It is the structural signature of a model encountering a language it was not trained for, and producing the phonetically-nearest output it knows — usually English.
We ran the same six-system matrix — whisper-1, gpt-4o-transcribe, gemini-2.5-flash, Google STT v2 Chirp 2 (fr-FR and wo-SN probe), and Kuma's end-to-end pipeline — across 104 Senegalese voice samples. The full numbers, the methodology, and 22 documented failure modes live in the State of Wolof Voice AI 2026 report. This post is a closer reading of one row in that table: whisper-1.
1. The headline number
whisper-1 mean WER across the 104-sample corpus: 1.049. Median: 1.000. Standard deviation: 0.045. Zero hard errors — every API call returned a transcript. By comparison:
| System | Mean WER |
|---|---|
| Chirp 2 (wo-SN probe) | 0.730 |
| Kuma end-to-end | 0.773 |
| Whisper · gpt-4o-transcribe | 0.814 |
| Gemini 2.5 Flash | 0.892 |
| Chirp 2 (fr-FR) | 0.918 |
| Whisper · whisper-1 | 1.049 |
Every system above 0.7. The story of African voice AI in 2026 is not that one provider is solved and one is broken — it is that no off-the-shelf system is production-ready for Wolof out of the box. But whisper-1 is the floor, and the gap between it and its sibling gpt-4o-transcribe (0.814) is the most informative datapoint in the entire matrix: same vendor, same audio, quarter-of-a-WER apart.
2. Where the extra tokens come from
The 104 reference transcripts contain 1,352 tokens in total. whisper-1 emits 4,111 hypothesis tokens against them — roughly three tokens of model output for every one token actually spoken. The same audio fed to gpt-4o-transcribe returns 1,938 hypothesis tokens. Whisper-1 is not failing by giving up. It is failing by over-generating.
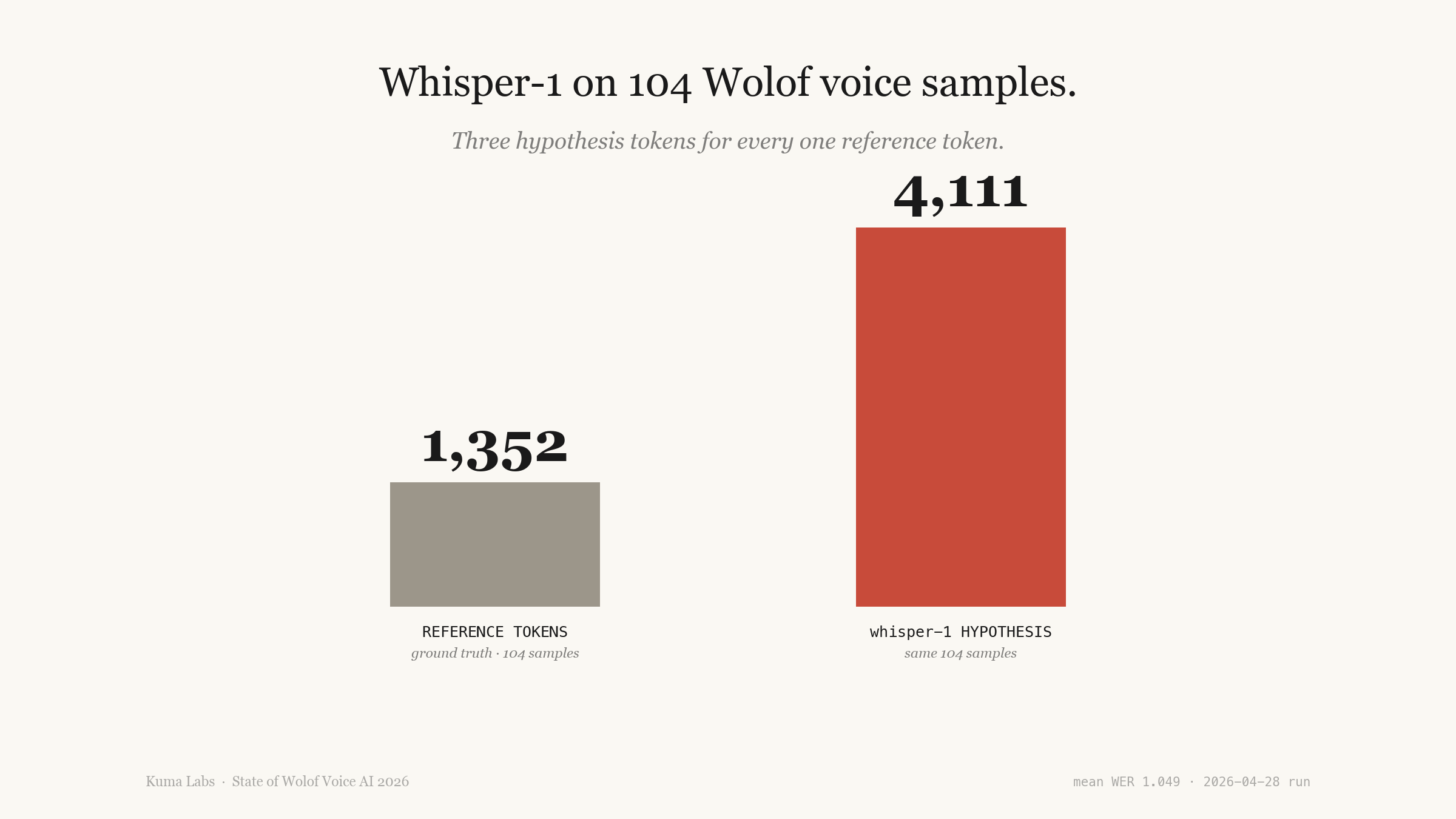
The pattern is consistent: when the model encounters a Wolof phoneme sequence it has no training distribution for, it produces the phonetically-nearest English continuation, then keeps going. A 15-token Wolof utterance becomes a 45-token English-flavoured paraphrase of nothing. The transcripts are syntactically valid English sentences; they are unrelated to the audio.
3. The "you" pattern on silence
Fed two seconds of near-silent audio — a single click, a breath, a microphone pop — whisper-1 reliably emits the single token "you". No error flag, no warning, no error code. The API returns 200 OK and a structurally valid transcript that contains exactly the wrong word.
| System | Output on near-silence |
|---|---|
| Whisper · whisper-1 | "you" |
| Whisper · gpt-4o-transcribe | "Damit" / "Thanks" |
| Gemini 2.5 Flash | French / German filler |
| Chirp 2 (wo-SN probe) | Digit sequence |
None of these outputs are labeled as silence. They arrive as normal transcription responses. A fintech integration that does not gate on silence at the client will receive plausible-looking transcripts on every accidental mic activation, every background-noise burst, every button mis-tap. The downstream pipeline parses them as if they were real speech. Failure 1·1 in the report walks through the full set of provider-divergent silence hallucinations.
4. The detected_language trap
The over-generation pattern in Section 2 is the loud version of Whisper-1's failure mode. Loud failures route around themselves — a downstream developer notices garbage output and adds a check. The dangerous failures are the ones that arrive as confident, fluent, grammatical French on Wolof input — clean enough that a French NLU pipeline downstream will process them rather than reject them.

What happened
Given the Wolof-French code-switched reference "Meun na léeb ba fukki junni ak Orange TikTak.", whisper-1 returned "J'ai pu le faire avec Fouki Juni et Orange Tic Tac." The Wolof numeral fukki junni became the proper noun Fouki Juni. detected_language came back as french. The downstream intent classifier returned nothing — it could not categorize the transcript as a credit request because, as French, it is not one.
This is the shape that matters for product teams. Loud failures (WER 1+, obvious garbage) are easy to handle defensively. Silent failures — syntactically valid French with a confident detected_language tag on Wolof input — pass through every reasonable check and arrive at the user as confident wrong answers. The full per-sample matrix is in the full report.
5. Where it's worst — French-accented Wolof
The 104-sample corpus is split across three locale tags: wo-SN (Wolof), fr-SN (French as spoken in Senegal, often by Wolof L1 speakers), and fr-FR (Senegalese French closer to a metropolitan accent). Whisper-1's segment WER:
| Segment | Mean WER |
|---|---|
| wo-SN (Wolof) | 1.134 |
| fr-FR (Senegalese French) | 1.022 |
| fr-SN (Wolof-L1 French) | 1.658 |
The model handles Wolof badly (1.13) but it handles French spoken with a Wolof accent dramatically worse (1.66). That is the median register of urban Dakar — most users in any consumer-facing voice product will speak this way. If you ship in Senegal and Whisper-1 is your ASR, the worst-performing segment is also the most-spoken one.
6. What this means for product teams
Three concrete things, in order of how cheap they are to ship:
- Gate silence at the client with a VAD before you call the ASR. Two seconds of WebRTC VAD eliminates the entire silence-hallucination class for every provider in the matrix, not just Whisper-1. It is free, deterministic, and runs in the browser.
- Don't trust
detected_languageon low-resource input. Whisper-1 returnsfrenchon Wolof code-switched audio with no warning. Downstream language routing that takes that field at face value will pipe Wolof traffic into a French NLU and produce confidently wrong answers. Either ignoredetected_languageentirely for content from regions with underrepresented languages, or treat it as a signal to be re-verified before routing. - Cap business-meaningful values at a plausible business maximum. The schema you accept is not the cap you should enforce. A merchant-payments schema that allows up to 10¹² will eventually receive 10¹¹. Pick a number an actual customer could plausibly transact in one utterance, and reject anything above it with a clear log line.
7. Why we still test it
whisper-1 is a 2022 model. The right framing is not "is Whisper-1 production-ready for African voice" — it isn't — but rather "how does each new generation move the curve". The 0.23 mean-WER gap between whisper-1 (1.05) and gpt-4o-transcribe (0.81) is what one generation of multilingual training did. The next generation will move it again, in some direction.
We will rerun the matrix when new versions ship and publish the diff. That is the entire job.
The full 22-failure catalogue, methodology, BibTeX, and per-provider breakdowns are in the State of Wolof Voice AI 2026 report. Frontier-lab and voice-product teams running Wolof or French-Senegalese voice in production can engage Kuma directly for an evaluation against your traffic.